
# 后端(Backend)
# 概述
后端是指真正的服务器所暴露出来的接口,它提供了节点所需要的数据。
后端可以是任何服务器。只要Melody能访问到他,比如,您可以创建从内部服务器获取数据的端点,并通过外部API(例如GitHub,Facebool或其他服务)添加第三方数据来丰富节点
后端的配置在每个节点的backends属性中声明
# 举个栗子
下面的配置中,Melody提供了一个节点/v1/user,当你请求该节点时,第二个后端配置毫无疑问,Melody会帮你做出代理请求"http://api-01.com/roles",但在第一个后端配置中提供了多个host,Melody则会帮你做负载均衡,每次选择最优的主机去代理请求。
{
"version": 1,
"endpoints": [
{
"endpoint": "/v1/name",
"method": "GET",
"backends": [
{
"url_pattern": "/name",
"host": [
"http://api-01.com",
"http://api-02.com"
]
},
{
"url_pattern": "/roles",
"host": [
"http://api-01.com"
]
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 数据处理
# 数据过滤
配置Melody节点时,您可以决定仅显示来自后端响应的字段子集,或更改返回的响应内容的结构,这个功能强烈推荐使用它来节省带宽
您可以使用以下两种策略来过滤内容:
- 黑名单
- 白名单
# 黑名单
配置了黑名单之后,Melody将从响应中删除列表中定义的所有匹配的字段,并将返回不匹配的字段。通过黑名单,可以排除响应中的某些字段。
黑名单的配置非常简单,只需要在banckend层级下配置blacklist数组即可,例如:
{
"endpoint": "/v1/user",
"backends": [
{
"url_pattern": "/back",
"blacklist": [
"token",
"password"
],
"host": [
"http://api.com"
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上述配置将会过滤掉token和password两个字段
并且注意在配置blacklist时,不需要考虑到分组group
但是需要考虑到是否配置了目标target,如果配置了目标target,则需要注意黑名单中配置的字段应该以target为根级别
# 白名单
配置了白名单之后,Melody仅会返回响应体中与白名单中匹配的字段和对应值,使用白名单将严格定义响应的内容。示例:
{
"endpoint": "/v1/user",
"backends": [
{
"url_pattern": "/back",
"whitelist": [
"name",
"id"
],
"host": [
"http://api.com"
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上述配置将只会返回响应中的name和id字段
白名单依然支持点字符
# 嵌套字符
当然如果你想过滤的字段并不是在最外层的结构中,他有可能被其他结构包裹,这时候你可以通过点运算符.去分割
{
"name": "Grant",
"age": 23,
"role": {
"name": "admin",
"uuid": "xxxxx"
}
}
2
3
4
5
6
7
8
例如上述结构,你可以通过role.uuid过滤该字段
注意
但是上述的点操作符只支持对象模式,如果有数组或集合结构,这种点操作符将不支持,你可以通过数组操作去处理
# 使用白名单还是黑名单?
白名单和黑名单这两种操作不能并存,只能二选一,如果两者都配置,
从性能角度来看,黑名单的速度优于白名单
# 分组(group)
Melody能将您的后端响应分组到不同的对象内,换句话说,当你为后端设置了group属性后,Melody不会将所有后端的请求直接合并到一起,而是会新建一个以group命名的对象,然后将该后端的响应填入该结构体,然后再将所有后端响应进行合并。
当不同的厚度按相应可能具有冲突的键名时,比如两个后端响应同时包含id字段,这是你可以通过分别为这两个后端响应设置分组来解决这个冲突
注意
对同一个节点下不同的后端设置分组时,不要设置相同的分组名,不然只会导致分组冲突,最终数据被覆盖。
# 分组示例
以下配置的是一个节点,该节点从两个不同的后端获取数据,但其中一个响应封装在分组last_post中
{
"version": 1,
"port": 8000,
"endpoints": [
{
"endpoint": "/findone/{name}",
"method": "GET",
"extra_config": {
"melody_proxy": {
"sequential": true
}
},
"output_encoding": "json",
"backends": [
{
"url_pattern": "/user/{name}",
"group": "base_info",
"method": "GET",
"blacklist": [
"id"
],
"host": [
"http://api.com"
]
},
{
"url_pattern": "/role/{resp0_base_info.role_id}",
"method": "GET",
"group": "role_info",
"host": [
"http://api.com"
]
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
调用接口/findone/{name}
curl -i "http://localhost:8000/findone/Grant"
得到分组后的响应
{
"base_info": {
"name": "Grant",
"role_id": 1
},
"role_info": {
"id": 1,
"name": "Administrator"
}
}
2
3
4
5
6
7
8
9
10
# 映射(mapping)
映射可以理解为重命名,可以更改后端响应的结构中的字段名,通过这个功能来适配不同的客户端而不需要更改后端代码
但是注意映射在目标提取和数据过滤之后,请确保映射的时候要映射的字段是否存在
比如上述的响应中的base_info.name字段你并不想用name,而是想改为user_name,上面有提到只是在数据过滤和目标提取之后,但是在分组之前,所以不用去管他的上面是否还有一层分组
{
"base_info": {
"name": "Grant",
"role_id": 1
},
"role_info": {
"id": 1,
"name": "Administrator"
}
}
2
3
4
5
6
7
8
9
10
你只需要在backend层加上mapping配置
{
"url_pattern": "/user/{name}",
"group": "base_info",
"method": "GET",
"mapping": {
"name": "user_name"
},
"blacklist": [
"id"
],
"host": [
"http://api.com"
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
响应结果将会变成
{
"base_info": {
"role_id": 1,
"user_name": "Grant"
},
"role_info": {
"id": 1,
"name": "Administrator"
}
}
2
3
4
5
6
7
8
9
10
# 目标提取
一般性在API中都会将数据封装在通用的结构中,例如data、content或者response,但是你并不希望每次都去获取子字段的数据,这时候你可以使用目标提取去获取你想要的字段,使之直接成为根级别的结构
注意,目标提取发生在数据过滤发生在数据处理的最先阶段,发生在其他操作之前
目标提取通过target属性来进行配置,该属性在backend层级
# 目标提取示例
我们有这样的一个后端api:/page,返回的响应是一个JSON对象
{
"page": {
"Name": "Page",
"Url": "hello.com",
"Title": "title"
}
}
2
3
4
5
6
7
但是我现在不想要page这一层,我想拿到的结果直接是Name、Url、Title作为根级别。可以通过下面的配置实现
{
"endpoints": [
{
"endpoint": "/newpage",
"backends": [
{
"url_pattern": "/page",
"target": "page",
"host": [
"http://api.com"
]
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
再去访问api/newpage,得到响应
{
"Name": "Page",
"Title": "title",
"Url": "hello.com"
}
2
3
4
5
# 集合操作(collections)
当后端响应集合或数组时,这是一种特殊的操作情况,上述的部分操作可能无法达到你的预期,有两种情况:
# 包装数组
后端响应整个都在数组之内
[
{
"a": 1
},
{
"b": 2
}
]
2
3
4
5
6
7
8
而前段想要拿到的是一个对象,应该包裹在{}之内,你可以通过声明"is_collection": true属性来实现如下效果,该属性是配置在backend层级的
{
"collection": [
{
"a": 1
},
{
"b": 2
}
]
}
2
3
4
5
6
7
8
9
10
这个key值collection是Melody默认提供的,当然你可以结合映射(mapping)来更改,示例如下
{
"endpoint": "/list",
"backends": [
{
"url_pattern": "/v1/list",
"is_collection": true,
"mapping": {
"collection": "list"
},
"host": [
"http://api.com"
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
得到的响应结构将会变成这样
{
"list": [
{
"a": 1
},
{
"b": 2
}
]
}
2
3
4
5
6
7
8
9
10
# 代理限速
无论客户端在节点级别生成多少请求流量,您都希望有效的控制Melody与后端的连接,后端的配置与节点层级的配置相似,但是声明在backend层级下
配置示例
{
"endpoint": "/v1/{test}",
"backends": [
{
"url_pattern": "/v1/{test}",
"extra_config": {
"melody_ratelimit_proxy": {
"maxRate": 100,
"capacity": 100
}
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
其中有两个参数你可以设置
maxRate此后端每秒接受的最大请求数capacity在令牌桶算法中有bucket capacity == added per second
# maxRate Vs clientMaxRate
maxRate(无论是在节点层还是后端(代理)层)是一个绝对值,您可以精确的控制允许到达后端或终结点的通信量。在DDoS中,maxRate由于无法接受超出允许范围的流量,因此可以有所帮助。
clientMaxRate是对每个客户端的限制,如果您只是想控制总流量,则它用不上,但是这样DDoS会完美的绕过节点层的流量限制,您可以通过设置clientMaxRate来将一些特定的滥用者限制在其限定的额度范围内。
# 断路器
为了保持Melody的响应能力,在后端代理的过程中添加了CircuitBreaker(断路器)中间件,通过此组件,当Melody要求的吞吐量超过实际的队长无法正常交付的吞吐量时,断路器机制将检测到故障并通过不发送可能会失败的请求来防止对服务器造成压力。通过防止由于超时等导致的失败请求过多,对于处理网络和其他通信问题也很有用。
断路器模式是通过简单的状态机来实现,监控该后端代理中的所有失败,当他们达到配置的阈值时,断路器将禁止代理更多的流量到后端。
# 怎样运行?
断路器通过一系列请求保留与您的后端的连接状态,并在开始时处于close状态,当它在给定的时间间隔(interval)内检测到的错误数达到了您所配置的连续故障数(maxErrors),断路器将会停止该后端所有的代理进入open状态,即断开所有与后端所有的交互,进行下一个N秒(timeout)的等待,等待时间窗口后,断路器将进入到half-open状态,该状态下一旦检测到代理错误将立即回到open状态等待时间窗口,如果检测到代理成功,则断路器恢复到close状态
# 断路器的三种状态
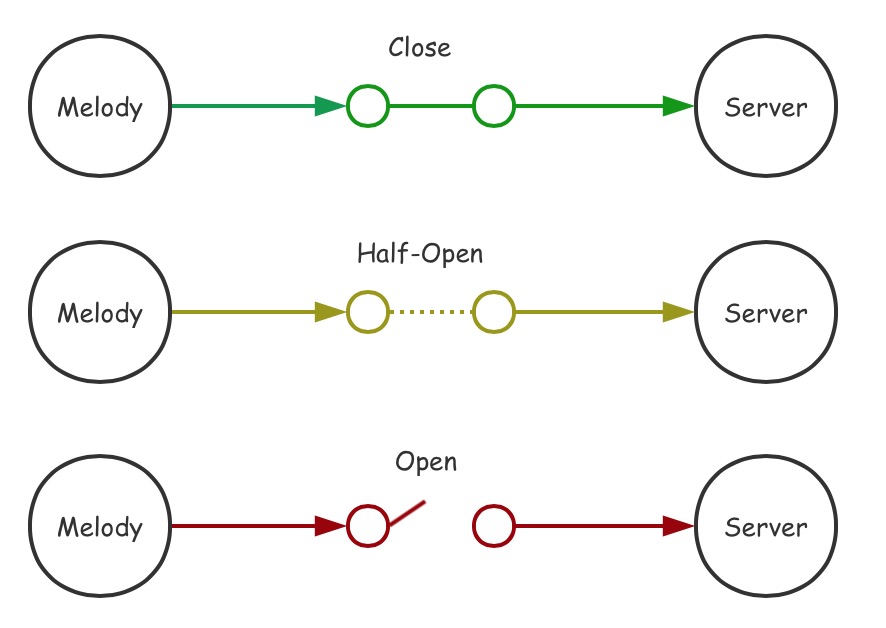
Close这是正常状态,当电路闭合时,电流不间断流动,并允许与服务器端连接交互Half-Open当系统遇到重复的问题时,仅允许进行必要的连接以测试服务器Open当电路段开时,不允许与服务器进行连接交互
# 断路器状态转换示意图
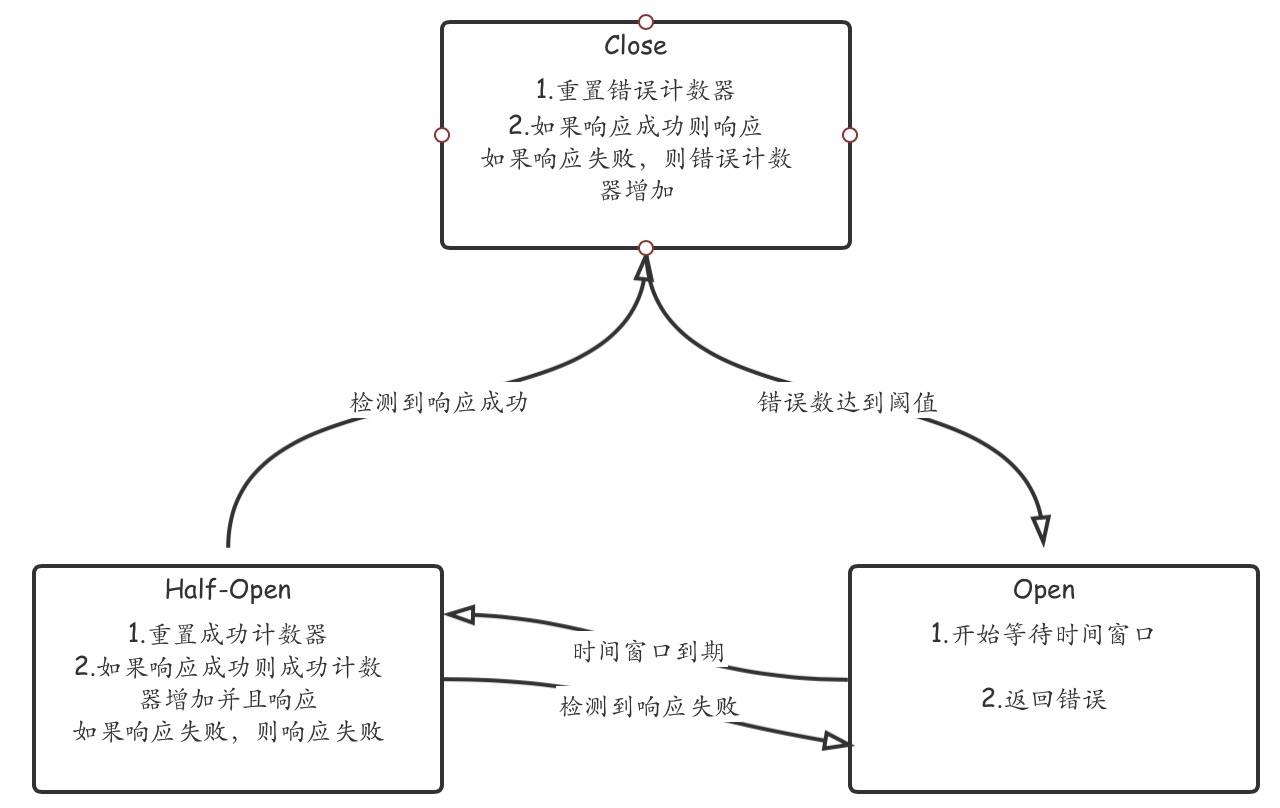
# 配置断路器
Melody将断路器作为中间件提供,您只需要在backend层的extra_config进行配置即可启用,具体配置如下所示
{
"endpoint": "/breaker",
"backends": [
{
"url_pattern": "/b",
"host": [
"http://api.com"
],
"extra_config": {
"melody_circuitbreaker": {
// 给定时间间隔(秒)
"interval": 60,
// 等待时间窗口(秒)
"timeout": 10,
// 连续故障数
"maxErrors": 1,
// 断路器状态改变时,是否log
"logStatusChange": true
}
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 编码支持
Melody可以解析来自使用不同编码的后端响应,例如:
- JSON
- XML
- RSS
- String
此外还有特殊的NO-OP
在每个backend层级都可以配置其专属的编码器,最终在节点响应中统一编码
下面的例子演示这一功能
{
"version": 1,
"endpoints": [
{
"endpoint": "/abc",
"output_encoding": "json",
"backends": [
{
"url_pattern": "/a",
"encoding": "json",
"host": [
"http://api.com"
]
},
{
"url_pattern": "/b",
"encoding": "xml",
"host": [
"http://api.com"
]
},
{
"url_pattern": "/c",
"encoding": "rss",
"host": [
"http://api.com"
]
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
最终来自于/a、/b、/c的三种编码的数据将被聚合成json响应
# 节点镜像
部署在测试环境或生产环境上的一套结构,不可能一直不更新,每当跟下,新老接口的集成总会导致大大小小的问题,往往这些问题很难排查。因此新街口的替换需要谨慎操作,如果直接投入使用就太冒险了,因为可能影响你的所有客户端。
节点镜像中间件,允许你测试在新功能增加之后的后端,Melody实际回去请求你的后端,但是响应只会作为镜像并且会被忽略,在最终的节点响应中也不会出镜像响应。
通过节点镜像,你可以:
- 通过log测试应用程序的错误
- 测试应用程序的性能
- 对比新旧服务的性能
- 检索其他可能由新接口导致的运行时问题
要启用节点镜像中间件,你只需要在backend层级的extra_config进行配置
{
"endpoint": "/shadow_backend",
"backends": [
{
"url_pattern": "/one",
"host": [
"http://api-01.com"
],
"extra_config": {
"melody_proxy": {
"shadow": true
}
}
},
{
"url_pattern": "/one",
"host": [
"http://api-02.com"
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
通过上述配置,在http://api-01.com和http://api-02.com都会有请求/one的日志打印,但是在最终的节点响应中,却只会有http://api-02.com/one的响应,并且响应头中的字段会表示请求已完整。
# 数组操作
数组操作中间件将数组结构展平和扩展来操作数组,该过程由flatmap组件完成,可以使您专注于要执行的操作类型。
注意
只有当响应是数组结构时,才能使用该中间件,否则如果响应为一般对象时,使用其他数据处理组件更为合适。
数组操作有两种操作类型:
move将元素从一个地方移动、嵌入、提取到另一个地方del删除特定的元素
上述两种配置都可以通过Melody中定义的表达式去定义
每一个操作被定义为两个属性的对象:type和args
定义操作的具体配置如下:
{
"extra_config": {
"melody_proxy": {
"flatmap_filter": [
{
"type": "move",
"args": ["source_in_collection", "target_in_collection"]
},
{
"type": "del",
"args": ["target_in_collection"]
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 运作方式
操作定义如下
- 移动:将元素移动或重命名
"type": "move""args": ["source_in_collection", "target_in_collection"]
- 删除:删除指定元素
"type": "del""args": ["target_in_collection"]
# 参考表
如下响应结构:
{
"a": [
{
"b1": [
{
"c": 1,
"d": "foo"
},
{
"c": 2,
"d": "bar"
}
],
"b2": true
},
{
"b1": [
{
"c": 3,
"d": "var"
}
]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
表达式对应值
| 表达式 | 值 |
|---|---|
a | a对应的整个数组 |
a.1 | a数组中的第二个对象{"b1": [{"c":3, "d": "var"}]} |
a.0.b1.0.d | "foo" |
a.1.b1.0.d | "var" |
a.*.b1.*.d | "foo" "bar" "var" |
a.*.*.*.d | "foo" "bar" "var" |